Data Deduplication On Windows Server 2016
Data deduplication was first introduced with Windows Server 2012 and improved upon in Windows Server 2016. To give you a high level overview of what Data Deduplication actually does, it goes through files in your fileserver and removes any redundant data to save on storage space. Since it uses a post-processing model, meaning it runs background jobs to optimize the files after the files have been created, data deduplication on Windows Server 2016 as well as Windows Server 2012 is completely transparent and very easy to work with.
How Data Deduplication Works on Windows Server
The data deduplication process works by removing any redundant data and ensuring that only a unique instance of any data is actually kept. All subsequent iterations of the data are then replaced with a pointer to the original, that pointer is known as a reparse point. Data deduplication can operate at the file, block or bit level. If two files are exactly alike in a file-level operation, one iteration of the file is retained and any subsequent copies have a pointer file pointing to the original location. I would not recommend using file deduplication because if the file is changed with the smallest update, a whole new file will be created because it is not exactly the same. Thus, making file-level deduplication highly inefficient.
Block deduplication and bit deduplication work slightly different because Windows looks within a file and saves unique iterations of each block. If a file is updated, only the data that has changed will be saved. As you can imagine, this is a far more efficient process than file-level deduplication because many of the same bits are retained and compression ratios are much greater.
Data Deduplication Jobs and Job Types
| Job | Description | Frequency |
|---|---|---|
| Optimization | Deduplicates data | Once an hour |
| Garbage Collection | reclaims disk space | Once a week |
| Integrity Scrubbing | Identifies corruption | Once a week |
| Unoptimization | Reverts optimization job | Manual |
The table above shows the 4 types of data deduplication jobs for Windows Server 2016 and below is a brief detail of what each job does.
-Optimization job: the optimization job is the main workhorse here and its job is to chunk the data, compress it, and then it store it in the chunk store. We can see that it runs once an hour by default.
-Garbage Collection job: the main function of the is clean the chunk store and reclaim any bits that no longer match the original chunks. By default, it runs once a week on Saturdays.
-Integrity Scrubbing job: This job also runs once a week on Saturday mornings. Its sole purpose is to identify corrupted data due to disk failures. If it does detect corruption, it will attempt to repair it. It actually keeps backup copies of the most popular chunks that are referenced the most times.
-Unoptimization job. And this is our undo job. This will take everything that deduplication did and put it back the way it was. So it’ll take all of those reparse points and fill it back up with the data that’s in the chunk store, get rid of the chunk store, and disable deduplication.
How to Enable Data Deduplication on Windows Server 2016
Data deduplication is a Windows Role so naturally we would use Roles and Features to enable it.
- Open Server Manager and click on Add roles and features.
- Select the default Role-based or feature-based installation radio button.
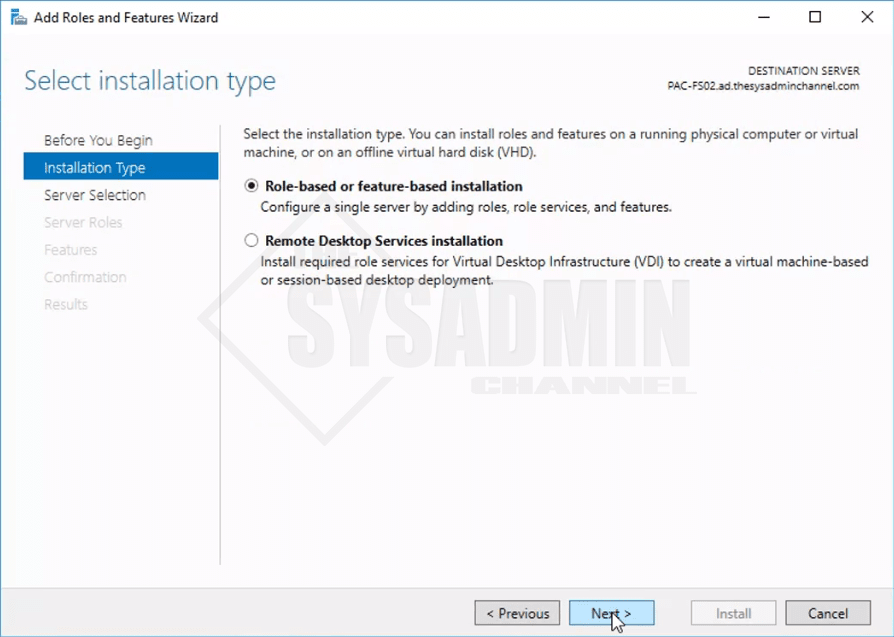
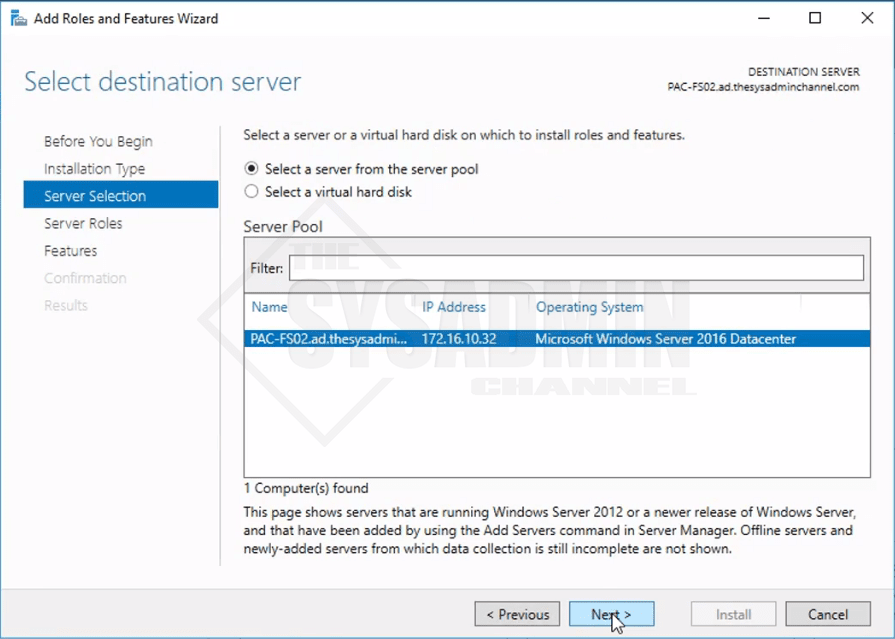
- Ensure select a server from the server pool is selected.
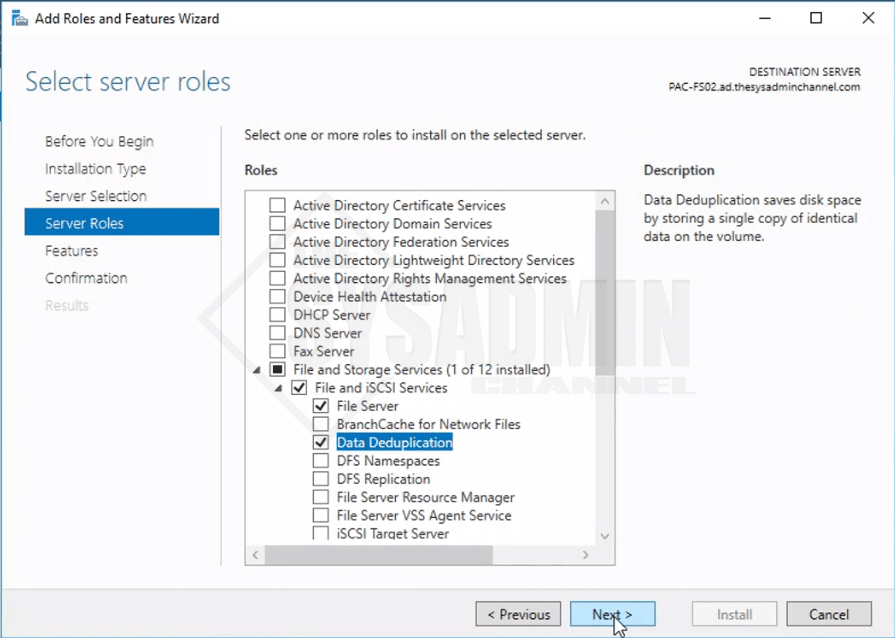
- Under File and Storages Services, you will see the option to enable Data Deduplication. Be sure to add the additional features when prompted.
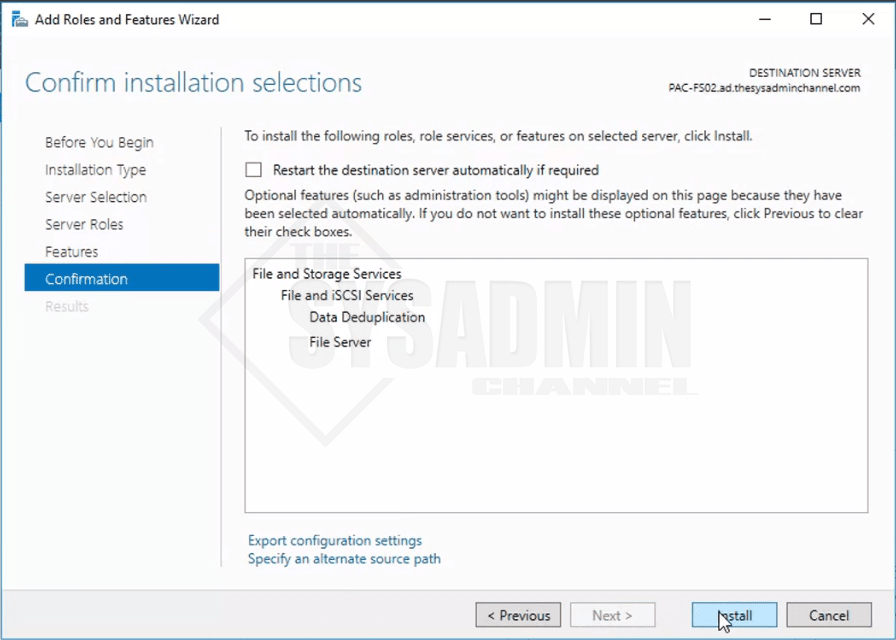
- If you added the features when it prompted, you don’t need to add any additional features in the features window.
- Once you’re ready go ahead and install. Reboot once it’s complete for safe measure
- Back in Server Manager expand the File and Storage Services -> Volumes -> right click drive letter Click Configure Data Deduplication.

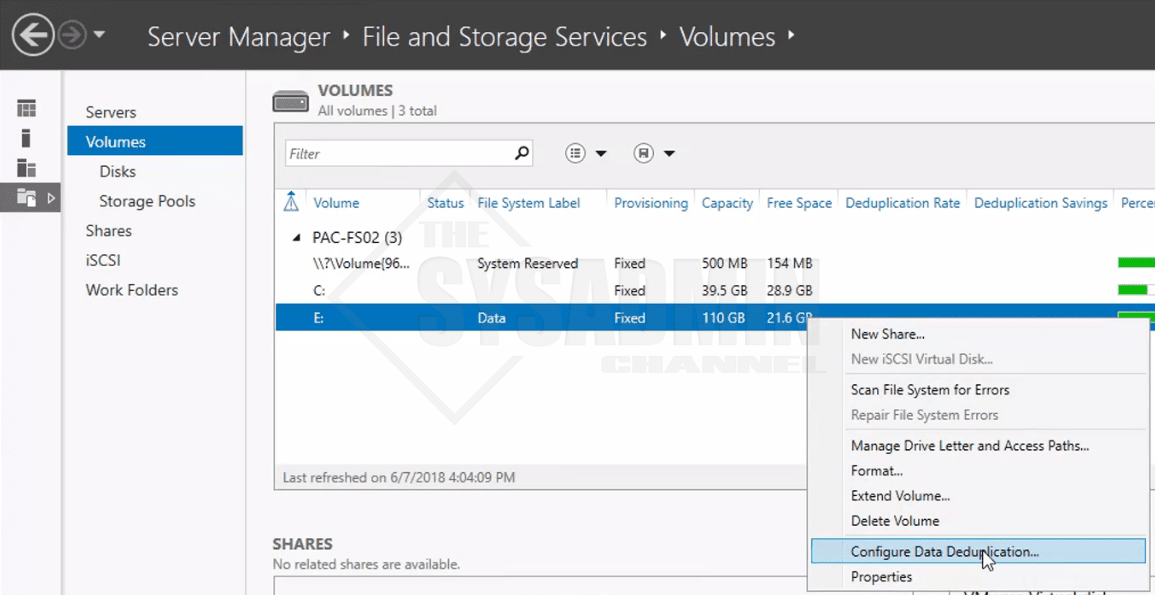
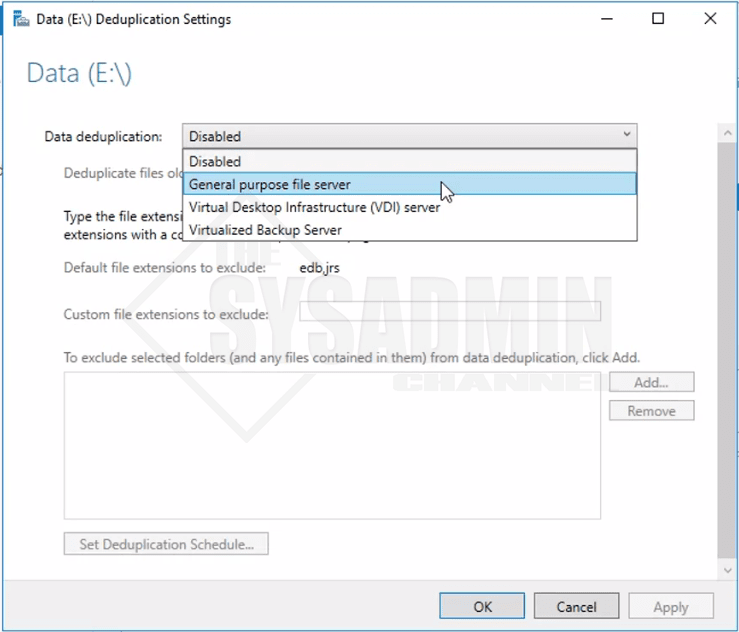
- By default Data Deduplication will be disabled when the role is added. Simply click on the drop down and select General File Purpose Server.
- After some time has passed you can open an administrative Powershell window and run the
Get-DedupStatuscmdlet. Here is a snapshot of a production server running data deduplication. Look at the Saved Space column.
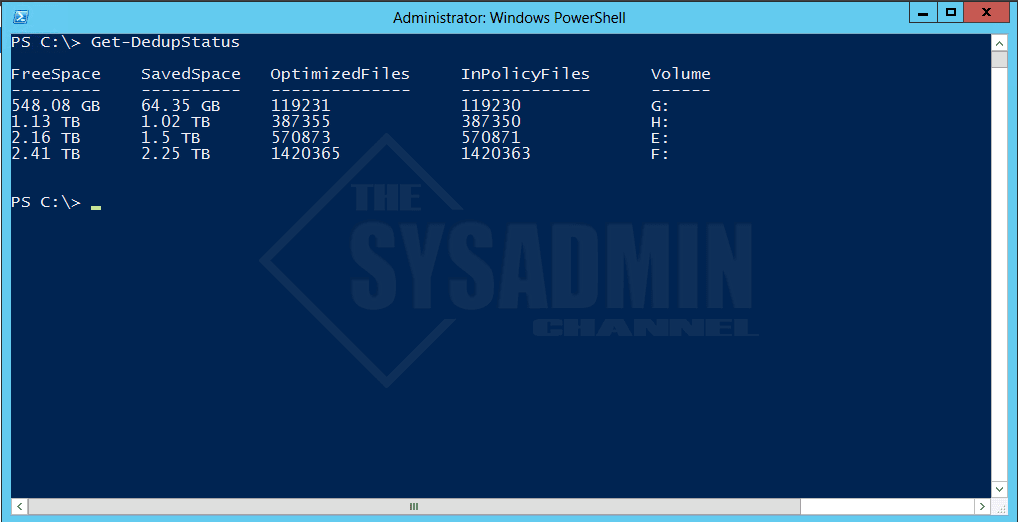
And that’s it. In this article we enabled Data Deduplication On Windows Server 2016 and saw the incredible space savings deduplication provides in Windows Server.
If you would like more awesome sysadmin content, be sure to check out our Youtube Channel for video demos and other cool sysadmin stuff.